The Customer Data Platform industry continues to grow as more buyers realize that CDPs offer to meet one of their most pressing needs: easy access to unified customer data. But the growth of CDPs has been accompanied by confusion as companies adopt the CDP label without providing what most people expect a CDP to deliver. To help clarify matters, the CDP Institute recently launched its RealCDPTM initiative, which defines a set of features that CDPs must meet to earn the RealCDP label.
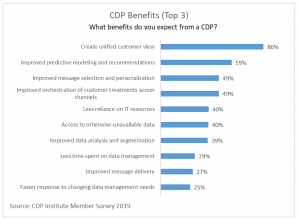
The logic behind RealCDP is that most people have an intuitive notion of what they expect a CDP to enable their company to accomplish and that CDPs need a specific set of features to make this possible. Of course, mind-reading is an inexact art but our research confirms what we suspected: When asked what they expect from CDP, people overwhelmingly say its job is to create a unified customer view.
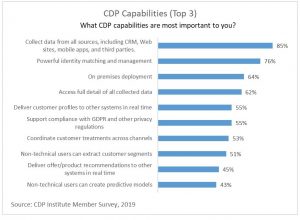
Digging a bit deeper, they understand this requires specific capabilities including data collection from all sources, identity matching to create unified customer profiles, and access to full details of all data.
The RealCDP requirements reflect these findings. It offers a five-point checklist:
- Ingest data from all sources
- Retain full detail of all ingested data
- Store the ingested data as long as the user wants
- Convert the data into unified customer profiles
- Make the profiles available to all external systems
The five points are designed to be a simple as possible, both so users can easily understand them and so we can objectively determine when a system meets them. But there are still nuances to consider.
- Ingest data from all sources. We define this to include structured data, such as purchase transactions; semi-structured data, such as Web browser history; and unstructured data, such as call center transcripts. But should it extend to video and audio files? Is it enough to just store the data or must the system add metadata to make it searchable? What tasks are required to add a new data source or element within an existing source? How much time is allowed to make the ingested data available? Our answers to all these are based on what we think users expect, again subject to mind-reading limitations. For this particular set of questions, the general answers are: we expect the CDP to handle common types of marketing data but not newer ones like audio files, and we think it’s okay to require a fair amount of technical effort to set things up.
- Retain full detail of all ingested data. Full detail is unambiguous, right? But it could mean the system stores an exact copy of the inputs or transforms them in a way that lets users reconstruct the detail if necessary. Transformation may sound less desirable but it’s often required to make the data usable for subsequent tasks, so there’s good reason to do it from the start. Similarly, there’s a need to impose structure on the imported data, so this topic includes questions about data models and deriving structured elements from unstructured data. In addition, it’s often necessary in practice to decide which details to retain, so we need to assess capabilities to sort through the inputs and keep only the good parts. Answers to these questions may not determine whether a system meets the requirements but they’re still important to users who might buy a system. So we want to gather them during the RealCDP process.
- Store the ingested data as long as the user wants. There’s no question that this one is vague. But user needs do vary and the core purpose of RealCDP is to ensure that each user gets what she needs. So we need to look at controls the system provides over data retention, including policies based on data source, age, risk, consent, and more. These questions spill into security and privacy requirements such as encryption, security certifications, consent gathering, permission compliance, and access audits.
- Convert the data into unified customer profiles. This gets to the essence of a single customer view and it raises many questions. What’s a customer? What kind of identity resolution is required? Does a profile need direct access to every bit of ingested data or is it okay to pre-select a subset of attributes that are available? What’s required to add model scores, segment assignments, and other derived features? How quickly must the profiles be updated after new information is ingested? The bar to pass this item can be set fairly low but we’ll want to clarify many of nuances so buyers can understand what they’re getting.
- Make the profiles available to all external systems. How are the profiles shared? Is a periodic file extract enough or do you need a real-time API? What functions are built into the API and what does it take to build a custom connector? Can the system need to create specialized extract formats such as database tables or AI training sets? How quickly must the system respond to a profile request? Does the system need a segmentation interface that builds complex selection statements? Does it need to accept complex external queries? Should the system include event-triggered and scheduled audience exports? Coming back to user expectations as a guide, it’s likely they expect something more than periodic file extracts but it’s not clear how much more.
The purpose of RealCDP is to reduce confusion, not increase it, so we’ll give yes or no answers for each of the five items. But we’ll also present some of the underlying details to help users understand what’s really included in a given system.
We’ll also clarify that there are other important topics for marketers that often come up, but are not covered by RealCDP. Real-time data processing is a big one; integrated identity resolution is another. Marketing applications such as predictive modeling, personalized message selection, and message delivery are also on the list. They’re not core to the RealCDP for various reasons but some users will find them essential. So we’ll at least indicate which systems provide some serious support in those areas without getting into the fine details.
RELATED ARTICLES
Demise of the DMP, Long Live the CDP
Building vs. Buying a CDP? Why That’s Not the Only Question You Should be Asking
